
无题
leetcoede学习杂项
2022/12/16
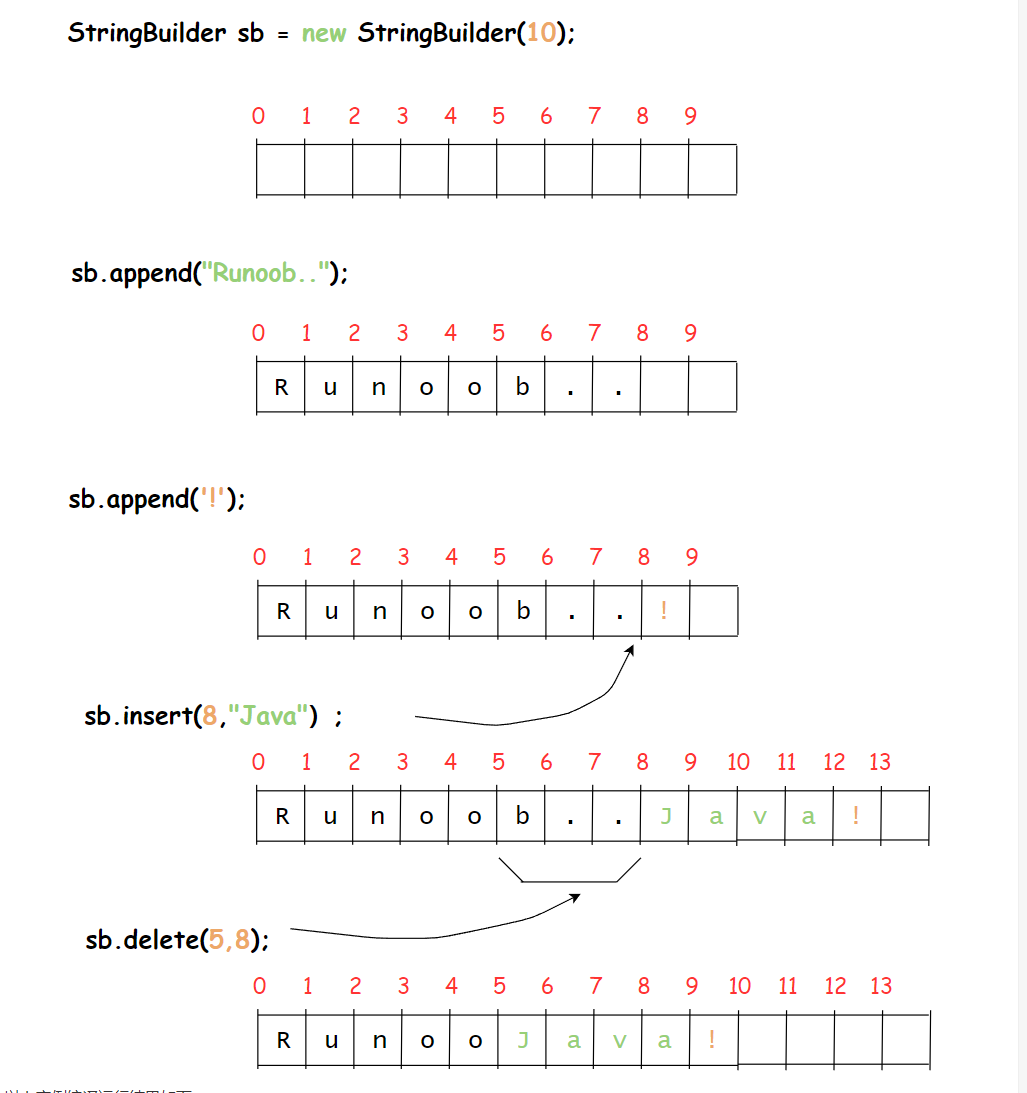
Java StringBuilder类
当对字符串进行修改的时候,需要使用 StringBuffer 和 StringBuilder 类。StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。(然而在应用程序要求线程安全的情况下,则必须使用 StringBuffer 类。)
Java charAt() 方法
charAt() 方法用于返回指定索引处字符串的字符。索引范围为从 0 到 length() - 1。
Java toString() 方法
toString() 方法用于返回以一个字符串表示的 Number 对象值。、
- toString(): 返回表示 Integer 值的 String 对象。
- toString(int i): 返回表示指定 int 的 String 对象。
1 | int[] a={1,3,4,56,6}; |
- 将StringBuilder类型变为String类
Java parseInt() 方法
- parseInt(String s): 返回用十进制参数表示的整数值。
- parseInt(int i): 使用指定基数的字符串参数表示的整数 (基数可以是 10, 2, 8, 或 16 等进制数) 。
parseInt()返回的是基本类型int
Java valueof 方法
valueOf()返回的是包装类Integer
2022/12/20
Java stream
什么是流
流是从支持数据处理操作的源生成的元素序列,源可以是数组、文件、集合、函数。流不是集合元素,它不是数据结构并不保存数据,它的主要目的在于计算
生成流
1、通过集合生成,应用中最常用的一种
1 | List<Integer> integerList = Arrays.asList(1, 2, 3, 4, 5, 6); |
2、通过数组生成
1 | int[] intArr = {1, 2, 3, 4, 5, 6}; |
通过Arrays.stream方法生成流,并且该方法生成的流是数值流(即IntStream)而不是 Stream。补充一点使用数值流可以避免计算过程中拆箱装箱,提高性能。
Stream API提供了mapToInt、mapToDouble、mapToLong三种方式将对象流(即Stream )转换成对应的数值流,同时提供了boxed方法将数值流转换为对象流.
3、通过值生成
1 | Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6); |
通过Stream的of方法生成流,通过Stream的empty方法可以生成一个空流。
4、通过文件生成
1 | Stream<String> lines = Files.lines(Paths.get("data.txt"), Charset.defaultCharset()); |
通过Files.line方法得到一个流,并且得到的每个流是给定文件中的一行.
5、通过函数生成
1 | Stream<Integer> stream = Stream.iterate(0, n -> n + 2).limit(5); |
iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断,只生成5个偶数。
generate方法接受一个参数,方法参数类型为Supplier ,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断。
流的操作类型级使用
https://blog.csdn.net/QiuHaoqian/article/details/120942134
2022/12/22
最大公约数与最小公倍数
最大公约数
辗转相除法
1 | int measure(int x, int y) |
辗转相减法
1 | int measure(int a,int b) |
穷举
1 | int measure(int x,int y) |
最小公倍数
两个数的乘积等于这两个数的最大公约数与最小公倍数的积
故可通过最大公约数求最小公倍数。(也可从小到大穷举)
2022/12/24
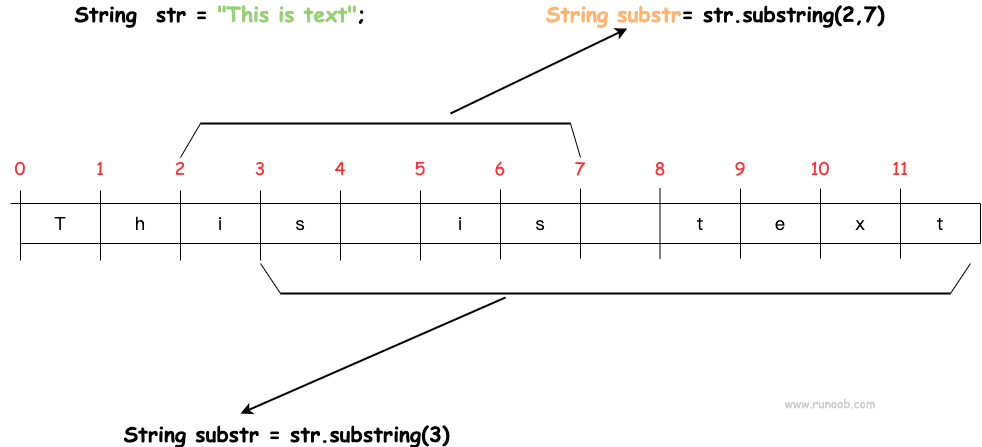
Java substring 方法
ps:左闭右开
2022/12/25
java copyOf方法
将一个数组的值传递给另一个数组


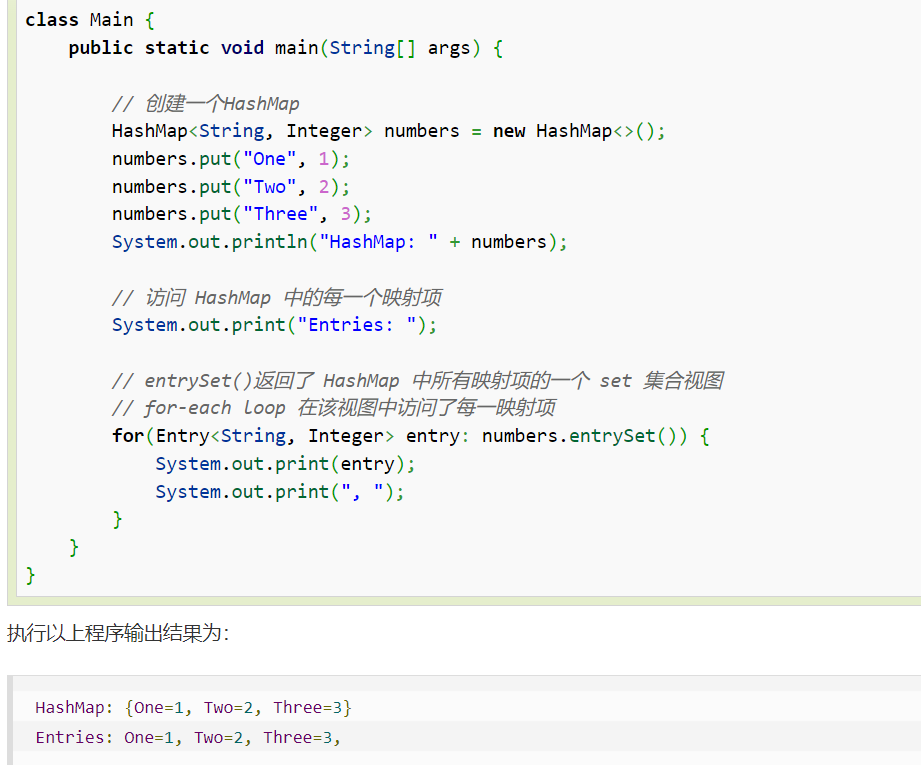
hash表
建立一个两个整数的hash表
1 | Map<Integer, Integer> map = new HashMap<>(Integer, Integer); |
使用.getOrDefault .put方法
put前记得get原来的值
containsKey() 方法 :如果 hashMap 中存在指定的 key 对应的映射关系返回 true,否则返回 false。
contains方法:判断key或value是否存在
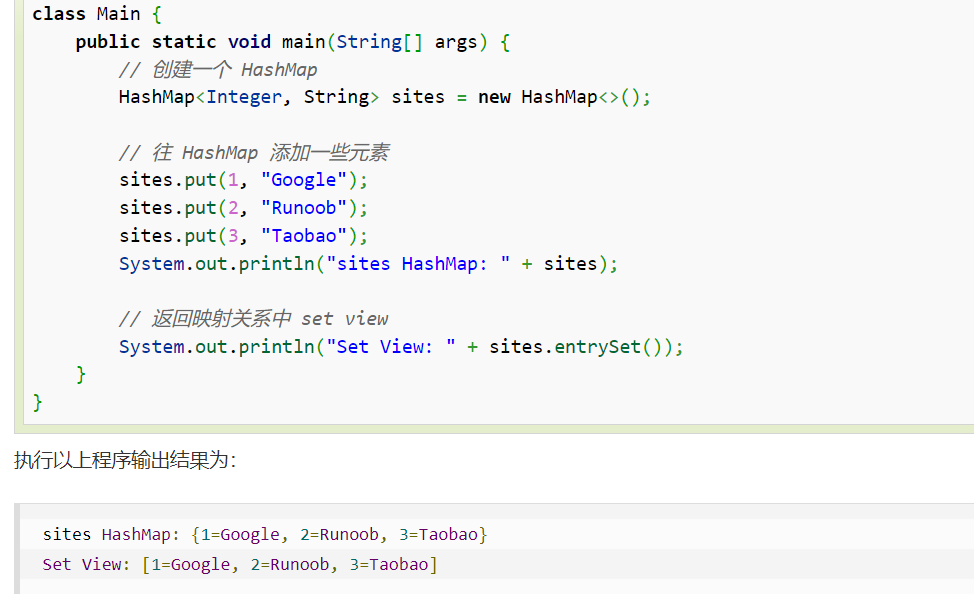
entrySet() 方法:返回此映射中包含的映射的 Set 视图。
- 注意:Set 视图意思是 HashMap 中所有的键值对都被看作是一个 set 集合。
1 | for (Map.Entry<Character, Integer> entry : position.entrySet()) |
arraycopy方法
1 | public static void arraycopy(Object src, int srcPos, Object dest, int destPos, int length) |
src:源数组;
srcPos:源数组要复制的起始位置;
dest:目的数组;
destPos:目的数组放置的起始位置;
length:复制的长度.
2022/12/26
二维数组的一维转换

2022/12/28
java indexOf()方法
1、int indexOf(String str) :返回第一次出现的指定子字符串在此字符串中的索引。
2、int indexOf(String str, intstartIndex):从指定的索引处开始,返回第一次出现的指定子字符串在此字符串中的索引。
3、int lastIndexOf(String str) :返回在此字符串中最右边出现的指定子字符串的索引。
4、intlastIndexOf(String str, int startIndex):从指定的索引处开始向后搜索,返回在此字符串中最后一次出现的指定子字符串的索引。
Java toCharArray方法
String.toCharArray()将字符串变为字符数组
2022/12/29
Hashset
HashSet 实际上是HashMap
- HashSet不能保证元素的存取顺序一致
- 可以存放null值,但是只能有一个null
- 不能有重复的元素
- HashSet线程不安全
- 没有带索引的方法,所以不能通过普通for循环进行遍历
在执行add方法后,会返回一个boolean值,可以通过 remove 指定删除哪个对象

Java set
Set集合类似于一个瓶罐子,集合中的多个对象之间没有明显的顺序排列。
set集合不允许包含相同的元素,如果试图要把两个相同的元素加入到同一个Set集合中,则将添加失败;add方法返回false,且新元素不会被加入。【无序容器】
最常用的实现类有HashSet、LinkedHashSet和TreeSet;
ArrayList
ArrayList类是一个特殊的数组–动态数组。通过添加和删除元素,就可以动态改变数组的长度。
支持自动改变大小
可以灵活的插入元素
可以灵活的删除元素
比一般的数组的速度慢一些
ArrayList是List接口的一个实现类。
ArrayList类是继承AbstractList抽象类和实现List接口的一个实现类。
因此,List接口不能被构造,也就是我们说的不能创建实例对象,但是我们可以像下面那样为List接口创建一个指向自己的对象引用,而ArrayList实现类的实例对象就在这充当了这个指向List接口的对象引用。
1 | //添加元素 |
List, Integer[], int[] 三者的互相转换
1 | import java.util.Arrays; |
StringBuilder 和String的转换
1 | String s = sb.toString(); |
int 和 String的转换
1 | // int -> String |
1 | //String -> int |
char字符数组与String
1 | //char字符数组转String |
1 | //String转char字符数组 |
使用 split() 方法注意如下:
- 如果用“.”或“|”作为分隔的话,必须是如下写法,String.split(“\.”) 或 String.split(“\|”),这样才能正确的分隔开,不能用 String.split(“.”) 或 String.split(“|”)。
Java split() 方法
split() 方法根据匹配给定的正则表达式来拆分字符串。
1 | public String[] split(String regex, int limit) |
. 、 **$**、 | 和 ***** 等转义字符,必须得加 \
多个分隔符,可以用 | 作为连字符。
eg:
1 | String str3 = new String("acount=? and uu =? or n=?"); |
2022/12/30
Java quene(队列)
队列是一种特殊的线性表,它只允许在表的前端进行删除操作,而在表的后端进行插入操作。
添加元素:add(失败时抛异常,不推荐)和offer(失败时返回false)
从队首获取元素并删除元素:remove(失败时抛异常,不推荐)和poll(失败时返回null)
- 不要把null添加到队列中,否则poll()方法返回null时,很难确定是取到了null元素还是队列为空。
获取队首元素但并不从队列中删除:element(失败时抛异常,不推荐)和 peek(失败时返回null)
isempty方法检查是否为空
Java PriorityQuene(优先队列)
每一个元素都多了一个优先级
1 | Queue<String> q = new PriorityQueue<>(); |
PriorityQueue允许我们提供一个Comparator对象来判断两个元素的顺序
1 | PriorityQueue<int[]> buyOrders = new PriorityQueue<int[]>((a, b) -> b[0] - a[0]); //降序排列 |
优先队列的遍历
1 | while (!sellOrders.isEmpty()){ |
2022/12/31
栈(stack)
栈是一种后进先出的数据结构
Stack只有入栈和出栈的操作:
- 把元素压栈:push(E)。
- 把栈顶的元素“弹出”:pop()。
- 取栈顶元素但不弹出:peek()。
在Java中,我们用Deque可以实现Stack的功能:
(因为Java有个遗留类名字就叫Stack,出于兼容性考虑,没办法创建Stack接口,只能用Deque接口来“模拟”一个Stack了。)
- 把元素压栈:push(E)/addFirst(E);
- 把栈顶的元素“弹出”:pop()/removeFirst();
- 取栈顶元素但不弹出:peek()/peekFirst()。
ps:当我们把Deque作为Stack使用时,注意只调用push()/pop()/peek()方法,不要调用addFirst()/removeFirst()/peekFirst()方法,这样代码更加清晰。
2023/1/1
DFS
DFS专注于递归:从起点开始,在一个方向上遍历完所有的点之后,才可以改变方向.所以,DFS的搜索过程很像“不撞南墙不回头”,这就是“深度优先搜索算法”中“深度”的由来。DFS则用于寻找所有的解,空间效率较高,而且找到的解不一定是最优解,所以需要记录并完成整个搜索,所以一般来说,深度搜索需要非常高效的剪枝
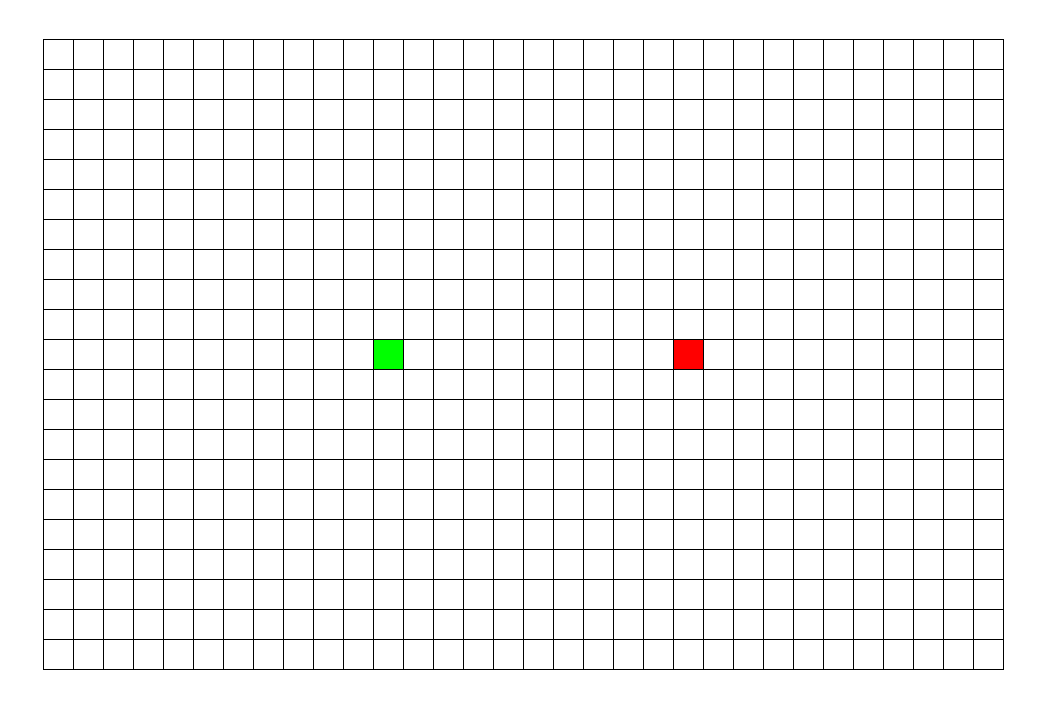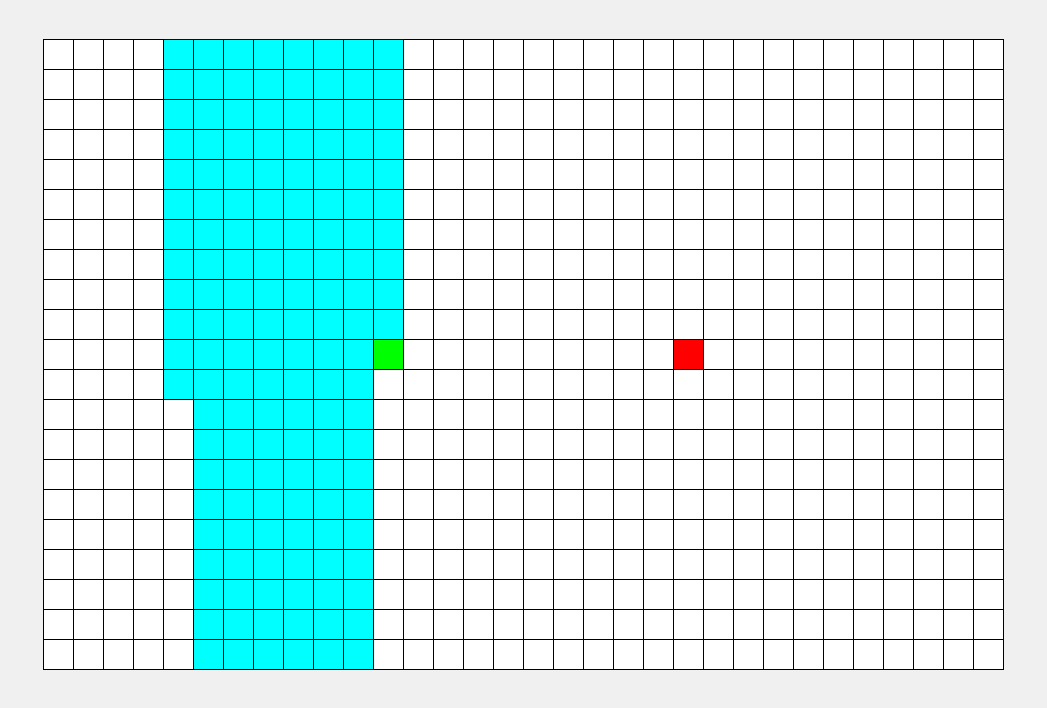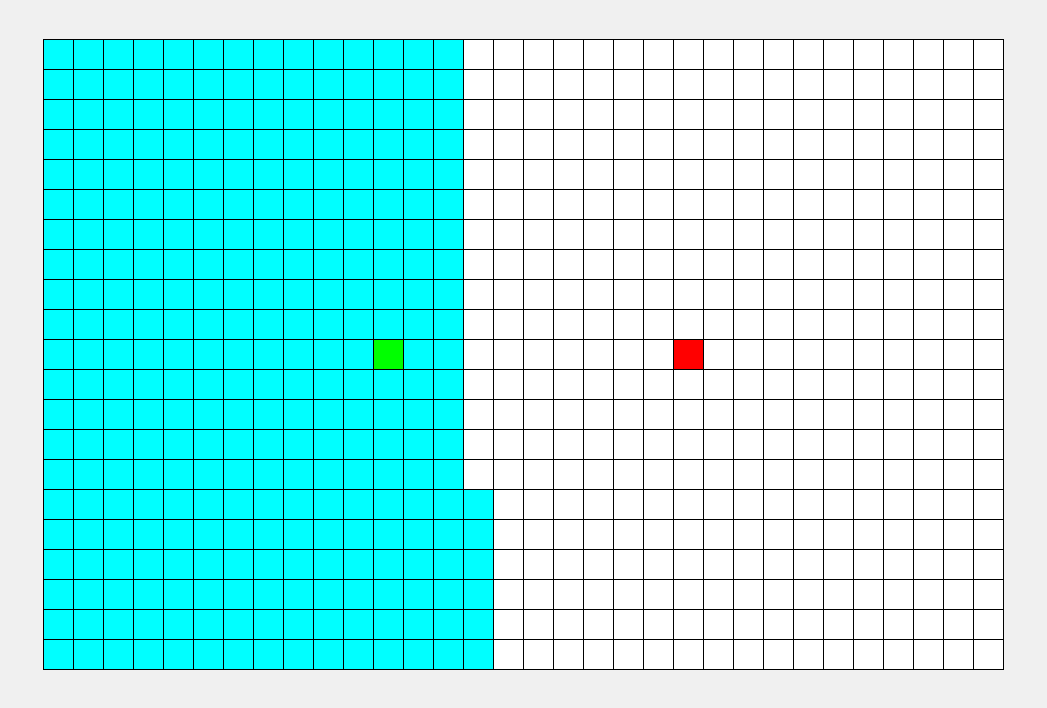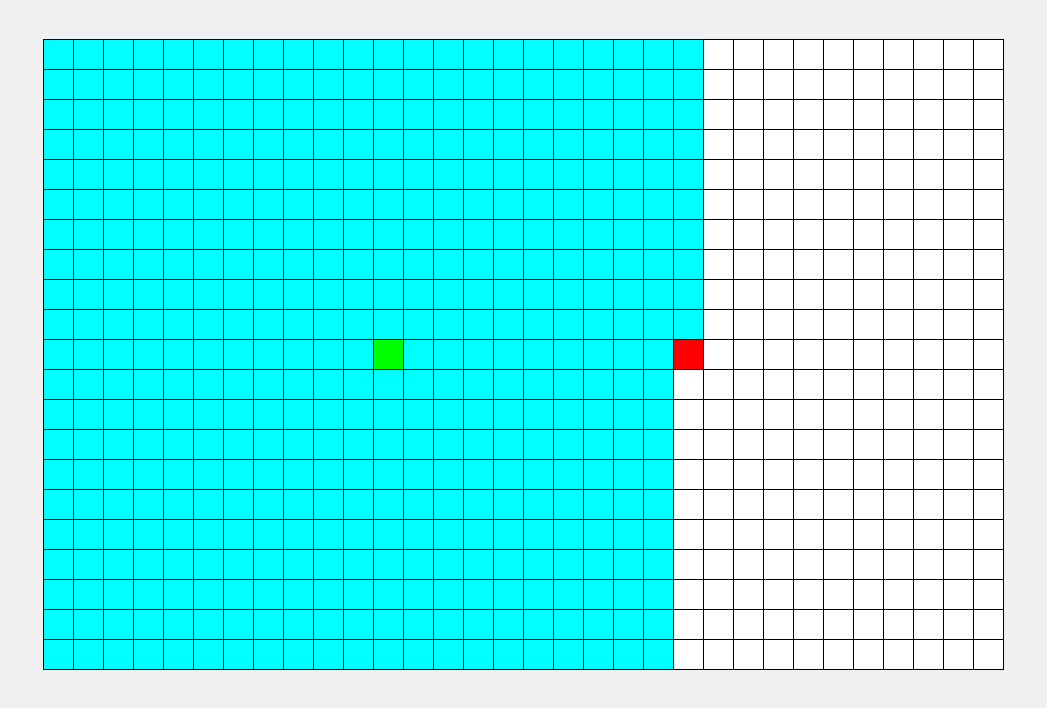
BFS
BFS专注于队列:从起点开始,对于每个离开队列的点,您必须遍历它周围的点。所以BFS的搜索过程很像“往湖里扔石头激起层层涟漪”,这就是“广度优先搜索算法”中“广度”的由来。BFS常用于寻找单一的最短路径,其特点是‘寻找最优解’。
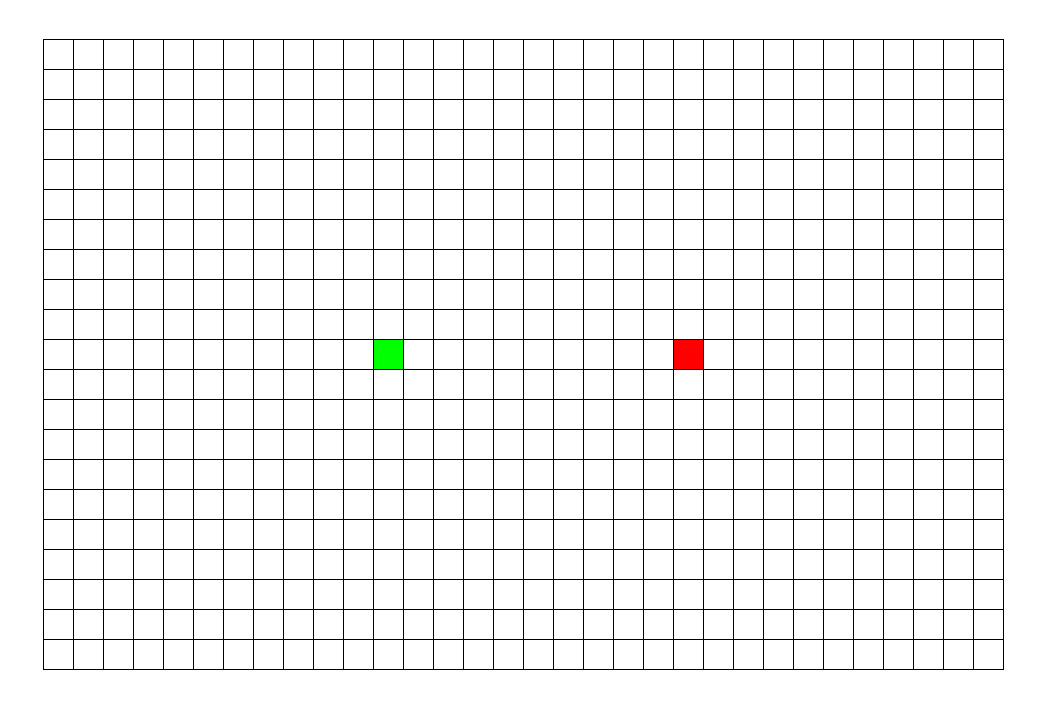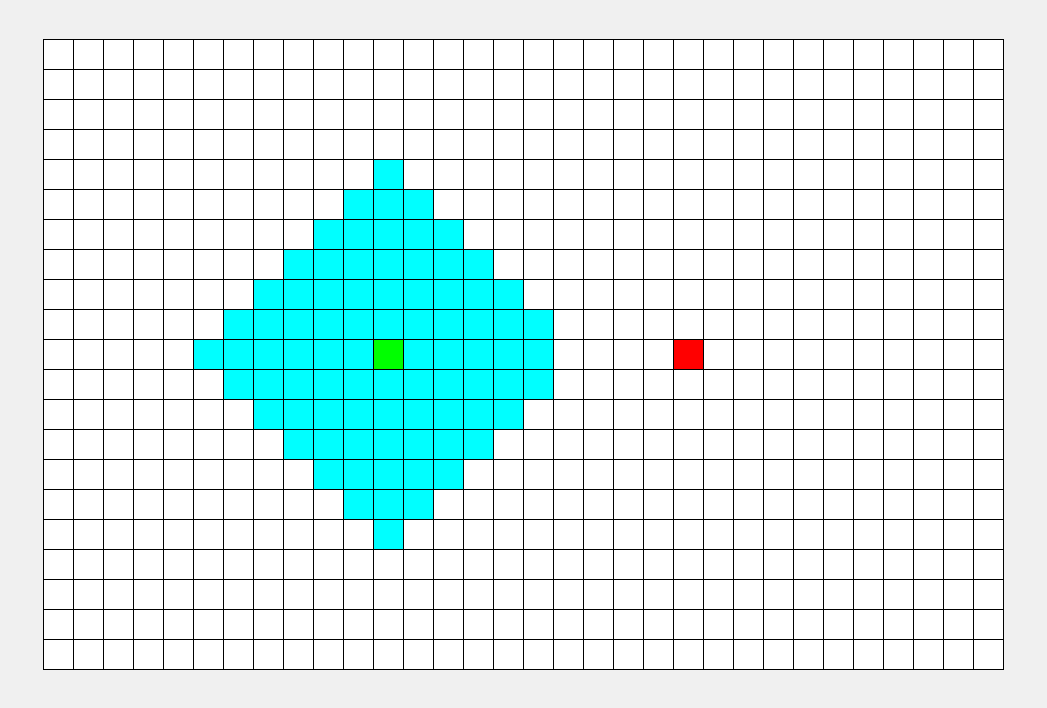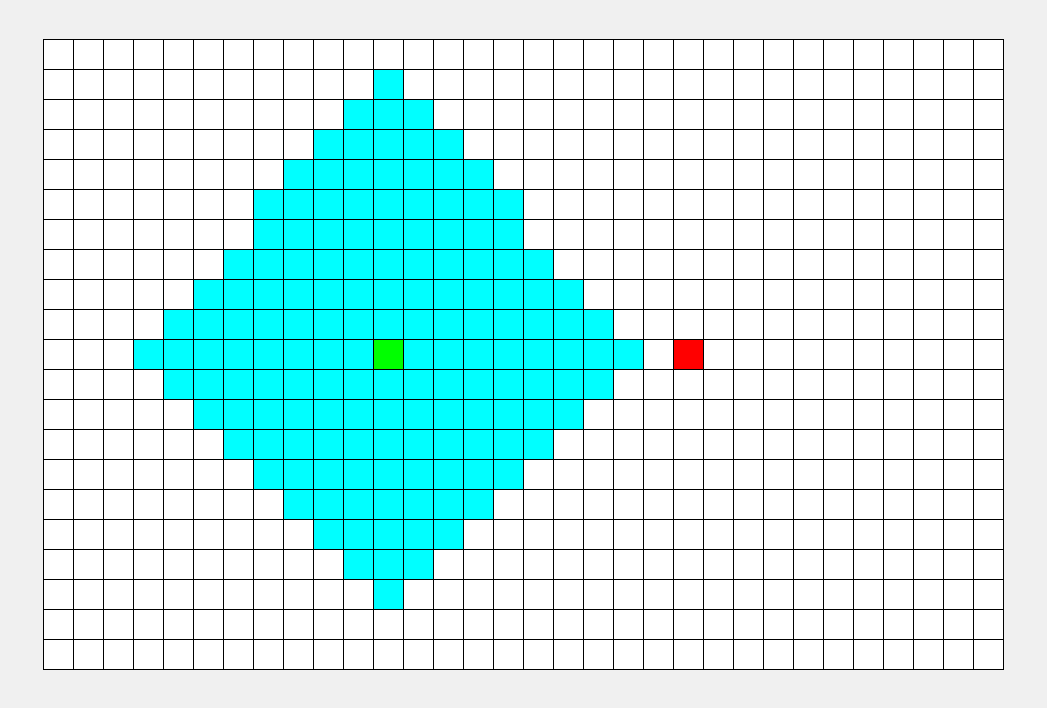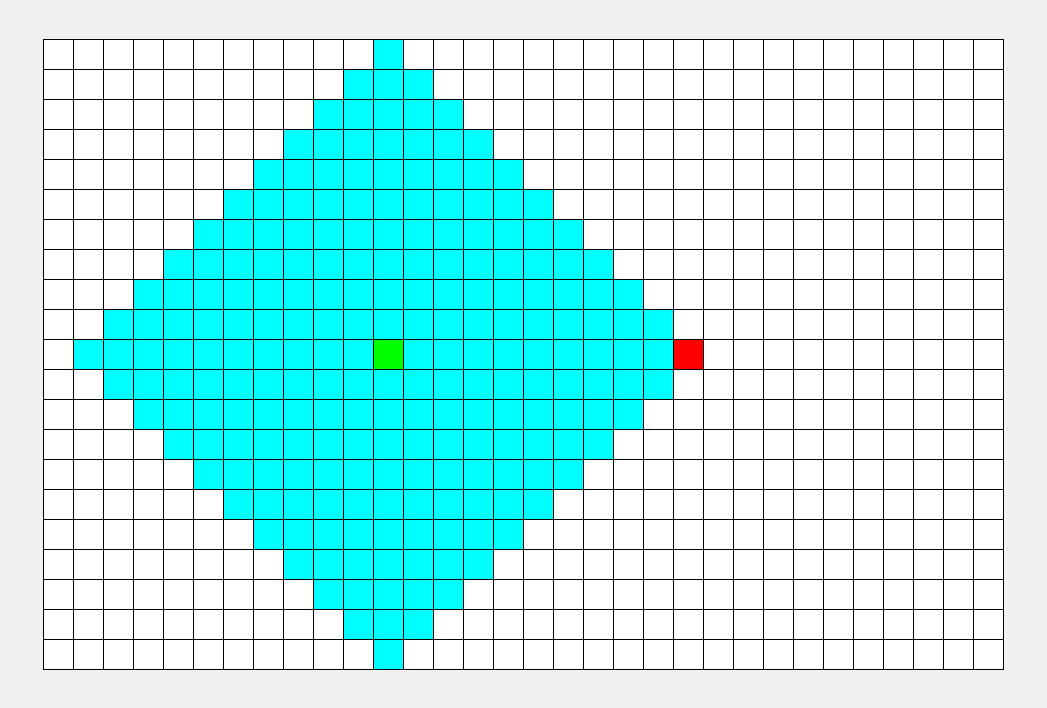
2023/1/3
Character类
Character.isDigit 方法
- 判断字符是否为数字,返回bool值
Character.isWhitespace() 方法
- 判断字符是否为空白字符,空白字符包含:空格、tab键、换行符。
Character.isUpperCase() 方法
- 判断字符是否为大写字母
Character.isLowerCase() 方法
- 判断字符是否为小写字母
Character.toUpperCase() 方法 (.toLowerCase())
- 将小写字符转换为大写(将大写字符转换为小写)
Character.toString() 方法
- 返回一个表示指定 char 值的 String 对象。结果是长度为 1 的字符串,仅由指定的 char 组成
1 | public static void main(String args[]) { |